The how: Building the site structure
I started my information architecture with my existing WordPress site architecture. Then I started to put all the content pieces together.
When you start with a decade-old information architecture that evolved to include podcasts, it shouldn’t be surprising that very few parts of that structure end up in a new site.
I quickly decided it wasn’t worth maintaining my old personal and professional blog posts. Most were outdated and not helpful to the portfolio I wanted the site to be.
Content types
I designed three main content types (page types):
- Homepage, which included an intro, headshot, and galleries of the four most important, or recent, items that have been updated in three categories: podcasts, skills, and blog posts.
- Grid pages that are gallery pages with cards for each skill, blog post, and podcast episode.
- Details pages for each of the categories:
- Blog posts.
- Podcast episodes, including show notes and an episode player.
- More information about each of my skills, the relevant tools used, and any relation presentations or publications I’ve created.
Separating content from presentation
Making this actually happen involved a lot of experimenting. While I was building out the site there were grid template pages for each of those content types. Eventually I made the grid collection-agnostic.
Once I grasped how to use content programmatically, it opened my eyes to how much reusable structures like metadata make a difference in how content is sorted, filtered, and displayed.
Taking an active development role made it clear to me how structuring your content helps your developers and your readers. Abstracting my content taught me:
- Using metadata reduces input errors.
- You can restrict what’s entered via pipelines and/or linters.
- It makes it easier for people to contribute.
- Sites can have a consistent voice and experience.
- Your content is portable and easier to publish across multiple channels.
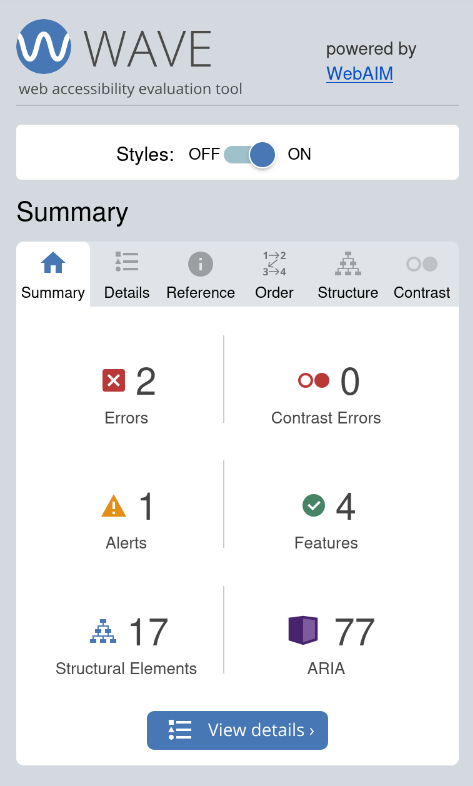
Accessibility
My wife is a developer and accessibility advocate. As a technical communicator, I wanted my site to be accessible to everyone. I was also able to programmatically use my metadata to populate <alt> tags. I used the WAVE browser plugin to test my pages and ensure they were accessible.